
Cheerio poznaliśmy już w poprzednim artykule. Teraz przedstawię jak napisać prosty scraper www na podstawie mojego skryptu. Pobieram dane ze strony internetowej, a następnie zapisuję do pliku JSON (wykorzystam go później w aplikacji Reactowej).
Czym jest scrapowanie stron internetowych?
Scrapowanie w kontekście IT to zbieranie informacji ze stron internetowych. Czyli „jakieś” narzędzie wchodzi na określoną stronę i pobiera wskazane informacje. Istnieje wiele gotowych scraperów, w tym artykule przedstawię jak zrobić to za pomocą Node.js.
Co będziemy scrapować? Cel artykułu
W artykule przedstawię jak pobrać informację ze strony internetowej – https://github.com/benmvp/frontend-confs. W tym repozytorium na Githubie znajdują się informacje na temat konferencji frontendowych. Przetworzę dane i zapiszę wszystko w pliku .json.
Dlaczego do pliku? Dane z pliku wykorzystam w aplikacji Reactowej – powstanie o tym kolejny artykuł.
Wszystkie pliki będą dostępne w repozytorium na Githubie (link na dole strony).
Lista konferencji frontendowych
Aplikacja znajduje się pod adresem: https://pbasiak.github.io/conferencesit/. Znajduje się tam lista konferencji frontendowych pobranego ze źródła powyżej. Aplikacja umożliwia wyszukiwanie po nazwie, filtrowanie po państwie, regionie lub mieście. Dostępna jest mapka, na której zaznaczone są miejsca tych konferencji. Każda konferencja posiada link do oficjalnej strony.
Niestety dane nie posiadają spójnego wzoru, przez co niektóre wyniki mogą być nieprawidłowe. Będę pracował nad aplikacją i poprawnością danych oraz rozwijał ją pod względem ilości konferencji.

Pisanie scrapera WWW – zaczynamy!
Wymagania
Przed rozpoczęciem należy upewnić się, że posiadamy następujące rzeczy:
- Node.js (użyta wersja: 10.15.3)
- npm (użyta wersja: 6.6.0)
- edytor kodu (np. Visual Studio Code)
Utworzenie projektu
Pierwszym krokiem będzie utworzenie folderu
mkdir nodejs-scraperoraz inicjalizacja npma i uzupełnienia o potrzebne informacje.
npm init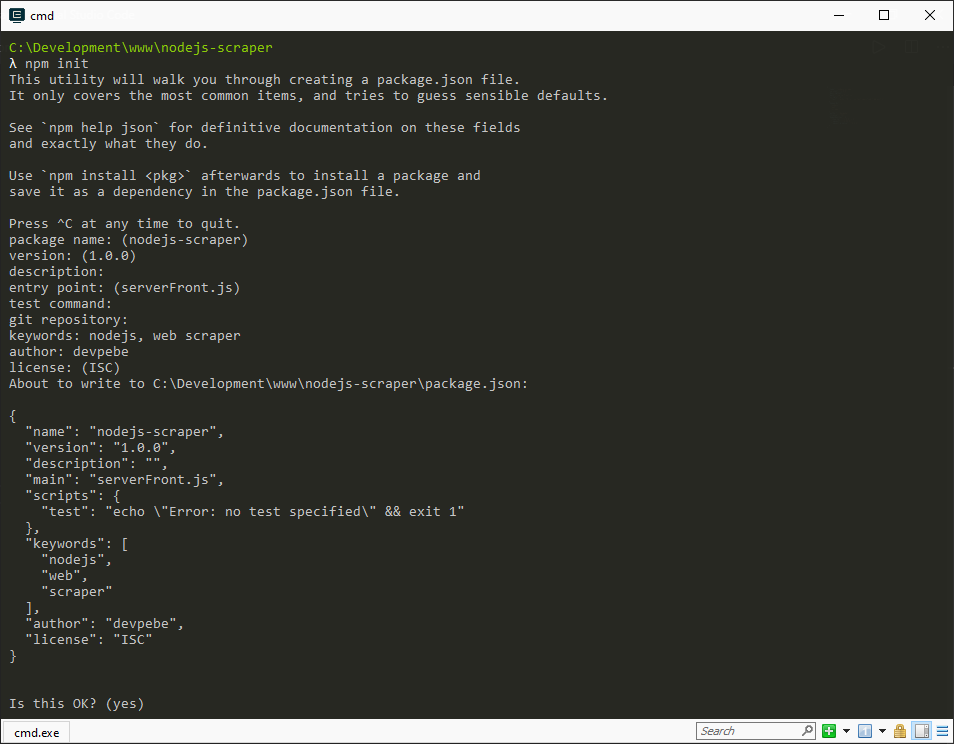
Instalacja pakietów – cheerio, request, request-promise
Do prawidłowego działania należy zainstalować pakiety za pomocą komendy:
npm install cheerio request request-promisecheerio
Cheerio odpowiada za parsowanie HTMLa. Więcej informacji można znaleźć w artykule, w którym opisałem bardziej szczegółowo bibliotekę cheerio.
request, request-promise
Biblioteki te odpowiadają za połączenie HTTP w aplikacji. Dzięki niej zostanie uzyskany kod HTML, który będzie parsowany za pomocą cheerio.
Plik główny
storeData – zapisywanie danych do pliku
const storeData = require('./modules/storeData');Funkcja, która odpowiada za zapisanie danych do pliku w formacie JSON. Więcej informacji na temat tej funkcji można znaleźć w artykule o zapisywaniu danych do pliku w Node.js.
Jako parametr przyjmuje dane i ścieżkę do pliku.
getFrontendData(function (frontendData) {
storeData(frontendData, frontendDataPath);
});frontendDataPath – ścieżka do zapisu pliku
const frontendDataPath = './data/frontendData.json';frontendDataPath to stała, w której została przypisana ścieżka do pliku, w którym mają zostać zapisane dane. Jest to parametr w funkcji storeData.
getFrontendData – główna funkcja
const getFrontendData = require('./modules/getFrontendData');W tej funkcji będzie się działo najwięcej.
Importowanie modułów
Na początku należy zaimportować moduły, które odpowiadają za połączenie HTTP oraz parsowanie HTML.
const rp = require('request-promise');
const $ = require('cheerio');getLocationOs – pobieranie koordynat latitude i longtitude
Funkcja odpowiada za pobieranie koordynat dla podanego wyrażenia np. „Warsaw, Poland„, a następnie zwraca latitude oraz longitude. Te dwie wartości będą potrzebne do wyświetlania miejsc na mapie.
const rp = require('request-promise');Do wykonywania połączenia ponownie importujemy request-promise.
const token = process.env.API_TOKEN; // GET YOUR TOKEN FROM MAPBOX APIDo poprawnego działania aplikacji wymagany jest token autoryzacyjny, który można zdobyć przez rejestrację w serwisie mapbox.
const locationUrl = `https://api.mapbox.com/geocoding/v5/mapbox.places/${query}.json?access_token=${token}&cachebuster=1567505858379&autocomplete=true`;Adres, w którym należy przekazać query (szukane miejsce) oraz token (pobierany z .env).
return rp(locationUrl)
.then(function (html) {
const result = JSON.parse(html);
const longitude = result.features[0].center[0];
const latitude = result.features[0].center[1];
return {
latitude,
longitude
};
})
.catch(function (err) {
console.log(err);
});Kod, który pobiera koordynaty nie dostaje zwrotki w postaci JSON (tak jak to bywa w przypadku standardowego API), tylko znajduje w HTMLu znacznik i pobiera zapisane tam koordynaty.
const longitude = result.features[0].center[0];
const latitude = result.features[0].center[1];Dlaczego? Szukałem najszybszego rozwiązania w celu pobrania tych wartości. Oczywiście zalecam zmianę powyższej funkcji, tak aby korzystała z API. Istnieje wiele takich API (zarówno płatne i darmowe rozwiązania).
return {
latitude,
longitude
};Funkcja zwraca dwie wartości – latitude i longitude.
Pobieranie danych z cheerio
Na początku należy znaleźć znacznik HTML w kodzie strony. W tym przypadku poszukuję znacznika, który jest wierszem w tabeli.
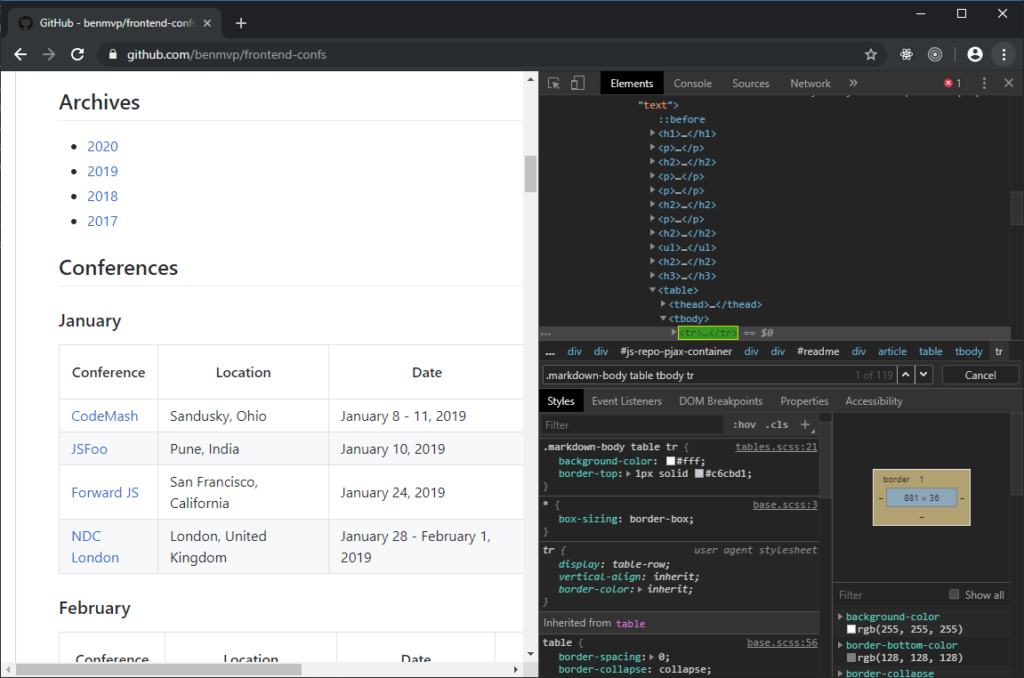
Wyrażenie, które zwróci wszystkie wiersze w tabeli wygląda następująco.
.markdown-body table tbody trNależy się upewnić czy xpath zwraca nam dane, których potrzebujemy, bez przypadkowych elementów.
Poniższy kod prezentuje parsowanie HTML przez cheerio.
const data = [];
$('.markdown-body table tbody tr', html).each(function (i, item) {
const name = $(item).children('td:nth-child(1)').text();
const url = $(item).children('td:nth-child(1)').children('a').attr('href');
const location = $(item).children('td:nth-child(2)').text().split(',');
const city = location[0];
const country = String(location[1]).trim();
const date = $(item).children('td:nth-child(3)').text().replace(',', '').split(' ');
const start_date = `${date[0]}.${date[1]}.${date[date.length - 1]}`;
for (i = 0; i < monthNames.length; i++) {
if (monthNames[i] === start_date[0]) {
start_date[0] = i + 1;
}
}
const dataItem = {
name: name,
url: url,
city: city,
country: country,
start_date: start_date,
category: 'frontend',
lat: '',
long: '',
};
if (Number(date[date.length - 1]) < Number(2019)) {
return;
}
data.push(dataItem);
});
return extendFrontendData(data).then(result => {
return callback(result);
})Tworzenie pustego obiektu
const data = [];Tablica, w której będą zapisywane obiekty każdego wiersza z tabeli.
Definicje obiektu
const name = $(item).children('td:nth-child(1)').text();Na początku są definicje stałych (przykład powyżej). W tych stałych zdefiniowane są odwołania do elementów (poprzez funkcję .children(’td:nth-child(1)’) – pobiera pierwszą komórkę, a z niej wartość tekstową) – każdej komórki np. name.
Każde inne pole jest pobierana analogicznie oraz są modyfikowane poprzez .split() lub .trim() – ważny jest format danych.
Definicja obiektu prezentuje się w taki sposób.
const dataItem = {
name: name,
url: url,
city: city,
country: country,
start_date: start_date,
category: 'frontend',
lat: '',
long: '',
};Dodawanie na stos
Na końcu funkcji dodajemy wynik na stos poprzez:
data.push(dataItem);Rozszerzamy obiekt o wartość latitude i longitude
return extendFrontendData(data).then(result => {
return callback(result);
})Wcześniej te pola zostały zdefiniowane jako puste stringi, teraz należy skorzystać z funkcji extendFrontendData, która wykorzystuje getLocationOs() i uzupełni każdy obiekt o te dwie wartości.
Powyższy callback wywołuje funkcję storeData, która kończy działanie i zapisuje wszystko do pliku, jeśli nie pojawi się żaden błąd.
const extendFrontendData = (frontendData) => {
const requests = frontendData.map((item) => {
return getLocationOs(item.country).then(data => {
return {
...item,
lat: data.latitude,
long: data.longitude,
};
}, data => {
return { item };
});
});
return Promise.all(requests);
};Uruchamiamy skrypt
node serverFront.jsWynik poprawnego działania skryptu jest następujący:
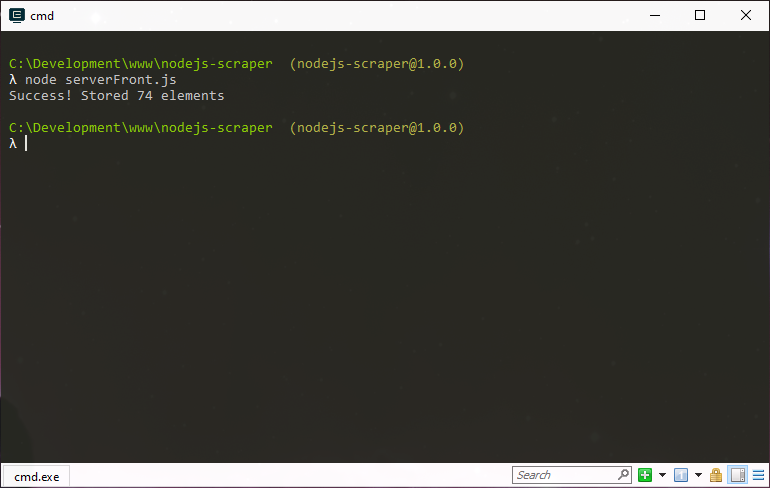
Rezultat
Sukces! Zapisały się 74 elementy!
Podsumowanie
W artykule przedstawiłem jak stworzyć prostego scrapera z pomocą Node.js. Zachęcam do napisania własnego – wystarczy, że będzie pobierał kilka prostych informacji.
Chcę jeszcze dodać, że kod nie jest optymalny i można jeszcze wiele rzeczy poprawić. W wolnych chwilach będę nad tym pracował. Oczywiście jeśli masz sugestie jak poprawić kod to daj znać! Code Review mile widziane!
Źródła i przydatne linki
Cały powyższy kod na GitHubie: https://github.com/pbasiak/nodejs-scraper
Artykuł na temat cheerio: https://devpebe.com/2019/10/14/parsowanie-html-w-node-js-za-pomoca-cheerio-jquery-dla-node-js/
Daj znać jeśli masz jakieś wątpliwości lub chcesz podzielić się własnym dziełem! 😊
Dodaj komentarz